



近年来,随着遥感科学技术的发展,遥感影像的分辨率大幅度提升,高分辨率遥感影像包含的细节特征及语义信息也随之剧增,传统的像素层解译分析已无法满足影像高层次内容的解译需求。如今的高分辨率遥感研究的前沿是面向对象处理、多尺度分析和场景理解。其中, 对象的提取与分割是基础,多尺度分析是手段,场景理解与认知是最终的目标[1]。因此,高分辨率遥感影像的场景分类成为遥感解译的一个重要方向。
传统的遥感影像场景分类方法分为两类:一是基于低层次特征的场景分类,主要是根据图像的颜色、纹理和形状等低层特征进行分类(如SIFT[2]、GIST[3]等),此类分类方法简单,但精度较低;二是基于中层特征的场景分类,中层特征是对低层特征的一种聚集和整合,其本质是通过对低层特征的统计分布分析建立与语义之间的联系[4],代表方法有视觉词袋BoVW[5]和K-means聚类方法[6]等,先提取底层特征聚类形成视觉词袋,再使用支持向量机训练分类。此类方法虽然精度相对提高,但仅使用局部特征信息且缺少特征间的关联性,仍然存在局限性。
伴随着深度学习算法在图像识别中崭露头角,越来越多的学者开始将其应用于遥感影像场景分类。文献[7]使用数据增广、dropout、正则化等方法,使卷积神经网络(convolutional neural network,CNN)具有更高的泛化能力,显著提高了分类精度。文献[8]利用预训练的AlexNet网络结合空间金字塔池化方法提高了场景分类精度。有研究表明,提取CNN的深层特征进行不同方式的特征融合,最终将融合特征输入SVM分类,效果优于CNN直接分类。文献[9]提取CNN的深层特征,进行重新排列组合后,使用不同尺寸大小和步长的卷积核进行卷积运算后进行分类。文献[10]提取不同尺度的CNN全连接层特征后使用SVM分类,在UCM、WHU-RS数据集上取得了较好的效果。虽然CNN深层特征能够表达图像的语义信息,但其多为高维语义信息。此外,由于特征融合多为简单地将多个特征向量连接得到新的特征向量,利用单核SVM分类在复杂的高分辨率遥感影像场景分类中仍有一定局限性。
为了解决特征维度高和单核SVM对融合特征分类受限的问题,本文基于低维卷积神经网络(LDCNN)[11]提取不同的深层次特征,并采用单层特征SVM分类,特征融合SVM分类及多层特征加权的多核SVM分类3种不同的分类方法,在2个公开数据集上进行场景分类试验,比较分类精度并进行分析。
1 原理和方法 1.1 网络结构和特征提取CNN网络一般包含卷积层、池化层、激活函数及全连接层。卷积层通过卷积核进行卷积运算提取特征;池化层对通过卷积层得到的特征进行压缩,减小数据量和运算量,保留了重要特征,避免过拟合;激活函数利用非线性函数对其进行映射,更好地表达特征,有效缓解过拟合现象;全连接层将卷积层或池化层得到的特征展开为一维特征连接分类器并进行分类。
多数的CNN网络(如AlexNet[12]等)全连接层输出4096-D的特征向量,但由于全连接层包含大量参数,容易发生过拟合,从而影响整个网络的泛化能力。本文使用一种低维的神经网络模型(LDCNN),并加上dropout进行微调,进一步提高网络的泛化能力。LDCNN模型在VGGM的基础上结合NIN改造完成,如图 1所示。保留VGGM的前5个卷积层删除全连接层,取而代之的为mlpconv层,即一个三层的感知器,可通过反向传播进行训练,并能为每个相应的类生成一个特征映射。最后通过全局池化层,计算特征的平均值并映射成n-D(n为分类类别数量)的特征向量,输入softmax进行分类。本文试验提取的为mlpconv层的后两层及global average pool层特征,分别用cppp1、cppp2和pool表示。

|
| 图 1 LDCNN结构 |
支持向量机是一种按监督学习方式对数据进行二元分类的广义线性分类器。SVM以统计学理论为基础,通过引入核函数,将低维非线性数据映射到高维特征空间中实现线性可分,其计算过程相对简单,稳定性较强[13]。常见的核函数有以下3种。
线性核(Linear)函数
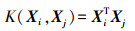 (1)
(1) 多项式核(Polynomial)函数
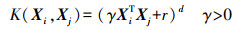 (2)
(2) 径向基核(RBF)核函数
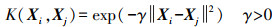 (3)
(3) 式中,Xi、Xj为输入的矩阵,T为矩阵的转置;d、r、γ均为不同核函数的参数。
常用的SVM都是单核的,即基于单个特征空间进行分类。在实际应用中往往需要根据经验选择不同的核函数、指定不同的参数,这样不仅不方便,而且当数据集特征为异构时效果并不理想。此外,由于高分辨率遥感影像的复杂性,单一的核函数很难满足分类要求,因此,利用多个核函数进行映射的多核学习模型随之产生。
多核模型比单个核函数具有更高的灵活性。在多核映射的背景下,高维空间成为由多个特征空间组合而成的组合空间。由于组合空间充分发挥了各个基本核的不同特征映射能力,因此能够将异构数据的不同特征分量分别通过相应的核函数得到解决。另外,对于提取的特征而言,多核SVM不用特征融合,可以直接对多层异构特征进行分类,从而避免了传统的特征融合中不同融合方法可能会改变特征遗漏信息的问题。目前,主流的多核学习方法主要包括合成核方法[14]、多尺度核方法[15]和无限核方法。
本文采用加权多核SVM集成的方法构建新的合成核(如图 2所示),利用权重将不同的核函数线性相加构建多核函数模型,以此训练分类器,不同的特征将被分别映射到最优的核函数以达到较高的分类效果。合成核K(Xi, Xj)的表达公式如下
 (4)
(4)

|
| 图 2 加权线性相加合成核 |
式中,km(Xi, Xj)为单个的基础核函数;dm为各个特征对应最优单个核函数的权重大小,权重总和为1。
2 试验及结果分析 2.1 数据集UCM(UC merced land-use)[16]数据集从美国地质调查局(USGS)的国家地图城市区域图像中获取,共分为21类场景,每类包含100幅256×256像素的图像,图像的像素分辨率为1英尺(约0.3 m),均为航空正射影像。
AID(aerial image data set)[17]是一个新的大型航空图像数据集,从Google Earth中获取,共有30个场景类别总计10 000个图像样本。每个类别的样本数量220~420不等。空间分辨率在0.5~8 m之间,图像大小为600×600像素。
2.2 试验参数设置本文中的CNN网络训练与特征提取采用MatConvNet深度学习框架完成。网络训练参数见表 1。
| 数据集 | 批量大小 (batch size) |
轮次数 (epoch) |
学习率 (learning rate) |
| UCM | 64 | 80 | 初始学习率为0.01,前40个epoch保持不变,之后每20个epoch,学习率衰减为之前的1/10 |
| AID | 80 | 80 |
其中,batch size代表每次输入网络模型的影像数量;epoch代表网络总共的循环训练次数;learning rate代表学习率;训练数据的占整个数据集的比重均为0.8;UCM和AID训练和测试图像的比例均为4∶1。
2.3 试验流程本文采用的试验流程为:①将预训练的网络VGG-M改造结构为LDCNN,并在UCM和AID 2个数据集上进行训练;②对于训练好的LDCNN,提取mlpconv结构的后两层cppp1和cppp2及全局池化层pool特征,利用不同的核函数进行SVM分类,寻找每个特征对应的最优核函数;③结合上一过程的最优核函数选择2个特征进行多特征加权多核SVM分类,使用固定梯度下降法循环寻找2个核函数之间的最优权重。
2.4 结果分析在UCM和AID 2个数据集上提取LDCNN深层特征,使用不同的核函数进行SVM分类,结果如图 3所示。3种特征cppp1、cppp2和pool对应的最优核函数在2个不同数据集上表现一致,cppp1和cppp2特征对应Linear核函数结果最优,而pool特征则对应RBF核。Linear核函数适用于线性可分的情况,线性可分的有利条件是高维特征和增大特征数量,cppp1(4×4×4096)和cppp2(4×4×N)相较于pool特征(1×1×N)为高维特征,因此使用Linear核函数效果更好。Polynomial核函数由于超参数众多,影响了模型的复杂性,对于较为简单的低维特征pool,参数较少的RBF核函数取得更好的效果。

|
| 图 3 LDCNN深层特征利用不同核函数SVM的分类结果 |
图 4为不同分类策略的分类结果比较,LDCNN代表可直接用softmax层分类;单层特征即图 3中准确率最高的特征层分类精度(cppp2);融合特征是将从上述3层提取的特征向量拉伸为一维向量并串联融合再输入SVM分类;多核SVM分类即选取图 3中最优的2个层的特征及其对应的最优核函数进行加权合成(cppp1-Linear+cppp2-Linear),利用合成核进行分类。由图 4可知,由于LDCNN网络结构的合理性,本身的分类精度已达到了较高的水平,在2个数据集上的精度均超过了95%。提取单层特征SVM分类,精度进一步提高,在UCM和AID上比LDCNN直接分类分别提高了2.4%和1.73%。特征融合后,包含信息更多,能够进一步提高分类精度,但是效果并不明显,分别提高了0.34%和0.6%,均不超过1%。

|
| 图 4 不同分类策略分别对UCM和AID的分类结果 |
使用加权多核SVM分类方法效果最好,它能够更好地结合各层特征不同维度的优点,新合成的核函数将特征充分映射到各自最优的子核函数,分类精度显著提高。在UCM与AID数据集上的分类精度为99.76%与99.5%,图 5、图 6为加权多核分类结果的混淆矩阵。由混淆矩阵可知,UCM数据集只在稀疏住宅和森林两个场景发生了互相错分,其他场景分类均正确,这是由于稀疏住宅周边大多为树林,在图像上和森林极为相像,如图 7(a)所示;AID数据集分类结果中,中心建筑、度假酒店和公园错分较低,也是由于与其他场景的相似性较大,特征不够明显,如图 8(a)、(b)所示。相较于传统的提取特征串联融合,此方法原理合理,效果显著。从两个数据集4种分类决策的精度变化曲线来看,多核SVM分类对AID数据集的分类精度提升明显高于UCM数据集,这是由于UCM数据集类别少且影像简单,现有的一些方法在其场景分类精度上已经能够达到近饱和的水平,而AID类别众多,数量大约是UCM的5倍,再加上其复杂的场景图像,更具有挑战性,多核SVM分类能够更好地挖掘复杂影像的特征,大幅提高分类精度。

|
| 图 5 UCM分类结果混淆矩阵 |

|
| 图 6 AID分类结果混淆矩阵 |

|
| 图 7 UCM中错分较高的场景图像对比 |

|
| 图 8 AID中错分较高的场景图像对比 |
在深度学习中,迁移学习是一种权重共享技术,减少了构建模型所需的训练数据、计算能力,且能够有效解决遥感影像场景分类中标签数据匮乏的问题,因此模型或方法的迁移性能也是重要的判别标准。利用多特征加权多核SVM分类后数据集之间的迁移学习能力显著提高。图 9、图 10、表 2为迁移学习的场景分类结果和混淆矩阵。由结果可知,用AID训练测试UCM的数据集结果明显优于UCM训练测试AID的结果,这是因为AID数据集相较于UCM影像数量和分类种类更多且更复杂,利用UCM训练测试AID是一种少量训练样本多测试样本情况。一些场景由于特征不明显,与其他场景存在相似性或场景本身分类标准的模糊(如UCM数据集中的交叉路口和立交桥、住宅和建筑等),如图 7(b)、(c)、(d)所示;AID数据集中的中心区域、商业区、学校、旅游景点等场景的分类精度较低,容易错分,如图 8所示。而对于一些特征明显场景内地物单一的场景(如飞机场、森林和停车场等),在2个数据集的互相迁移学习上均取得了较优的分类精度。另外,2个数据集之间的场景定义标准差异也会对迁移学习精度造成影响。

|
| 图 9 AID数据集迁移学习到UCM的分类结果混淆矩阵 |

|
| 图 10 UCM数据集迁移学习到AID的分类结果混淆矩阵 |
| (%) | |||||||||||||||||||||||||||||
| 类别 | 提取特征 | 特征融合 | 多核SVM分类 | ||||||||||||||||||||||||||
| AID训练测试UCM | 90.48 | 92.86 | 94.76 | ||||||||||||||||||||||||||
| UCM训练测试AID | 84.8 | 90.35 | 92.25 | ||||||||||||||||||||||||||
表 3比较了本文方法与现有方法对UCM和AID数据集的分类结果,由此可知本文方法在两个数据集上均取得了较理想的分类精度。
本文通过提取低维卷积神经网络的深层特征进行了多核SVM分类,相比于传统的深度学习网络模型和特征融合方法,本文方法在UCM和AID两个数据集上均取得了较高的分类精度。首先提取了LDCNN中感知器层的两个全连接层特征和最后的全局池化层特征;然后将各层特征利用不同的核函数进行SVM分类找到各特征对应的最优核函数;最后将两个最优层的特征及其对应的最优核函数加权合成为一个新的合成核进行多核SVM分类。试验结果表明,本文方法不仅能够很好地结合LDCNN中不同的深层特征,并将其分别映射到最优的核函数以达到较高的效果,而且具有很好的迁移学习能力。
| [1] |
李德仁, 童庆禧, 李荣兴, 等. 高分辨率对地观测的若干前沿科学问题[J]. 中国科学: 地球科学, 2012, 42(6): 805-813. |
| [2] |
LOWE D G. Object recognition from local scale-invariant features[C]//Proceedings of the Seventh IEEE International Conference on Computer Vision. Kerkyra: IEEE, 1999(2): 1150-1157.
|
| [3] |
WANG W, CAAMAÑO G P, WILDE E, et al. What is the gist? Understanding the use of public gists on GitHub[C]//2015 IEEE/ACM 12th Working Conference on Mining Software Repositories. Florence: IEEE, 2015: 314-323.
|
| [4] |
赵理君, 唐娉, 霍连志, 等. 图像场景分类中视觉词包模型方法综述[J]. 中国图象图形学报, 2014, 19(3): 333-343. |
| [5] |
王宇新, 郭禾, 何昌钦, 等. 用于图像场景分类的空间视觉词袋模型[J]. 计算机科学, 2011, 38(8): 265-268. DOI:10.3969/j.issn.1002-137X.2011.08.064 |
| [6] |
OKUMURA S, MAEDA N, NAKATA K, et al. Visual categorization method with a bag of PCA packed key points[C]//Proceedings of 4th International Congress on Image and Signal. Shanghai: IEEE, 2011, 950-953.
|
| [7] |
孟庆祥, 吴玄. 基于深度卷积神经网络的高分辨率遥感影像场景分类[J]. 测绘通报, 2019(7): 17-22. |
| [8] |
HAN X, ZHONG Y, CAO L, et al. Pre-trained AlexNet architecture with pyramid pooling and supervision for high spatial resolution remote sensing image scene classification[J]. Remote Sensing, 2017, 9(8): 848. DOI:10.3390/rs9080848 |
| [9] |
LIU N, LU X K, WAN L H, et al. Improving the separ-ability of deep features with discriminative convolution filters for RSI classification[J]. ISPRS International Journal of Geo-Information, 2018, 7(3): 95. DOI:10.3390/ijgi7030095 |
| [10] |
HU F, XIA G S, HU J W, et al. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery[J]. Remote Sensing, 2015, 7(11): 14680-14707. DOI:10.3390/rs71114680 |
| [11] |
ZHOU W X, NEWSAM S, LI C, et al. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval[J]. Remote Sensing, 2017, 9(5): 489. DOI:10.3390/rs9050489 |
| [12] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems. [S. l. ]: Curran Associates Inc., 2012: 1097-1105.
|
| [13] |
张学工. 关于统计学习理论与支持向量机[J]. 自动化学报, 2000, 6(1): 36-46. DOI:10.3969/j.issn.1003-8930.2000.01.009 |
| [14] |
李湘眷, 孙显, 王宏琦. 基于多核学习的高分辨率遥感图像目标检测方法[J]. 测绘科学, 2013, 38(5): 84-87. |
| [15] |
LIU Q, HANG R, SONG H, et al. Learning multiscale deep features for high-resolution satellite image scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(1): 117-126. DOI:10.1109/TGRS.2017.2743243 |
| [16] |
YANG Y, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, 2010: 270-279.
|
| [17] |
XIA G S, HU J, HU F, et al. AID: a benchmark dataset for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965-3981. DOI:10.1109/TGRS.2017.2685945 |
| [18] |
BI Q, QIN K, ZHANG H, et al. APDC-Net: attention pooling-based convolutional network for aerial scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(9): 1603-1607. DOI:10.1109/LGRS.2019.2949930 |
| [19] |
LU X, SUN H, ZHENG X. A feature aggregation convolu-tional neural network for remote sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(10): 7894-7906. DOI:10.1109/TGRS.2019.2917161 |
| [20] |
XU K J, HUANG H, LI Y. Multilayer feature fusion network for scene classification in remote sensing[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(11): 1894-1898. DOI:10.1109/LGRS.2019.2960026 |